
Assistente virtual, influenciadora, avatar, "mascotinha". Para nós, a Gia é tudo isso. No momento da criação, definimos que a Gia deveria amar tecnologia, ser espontânea e ter uma didática descomplicada.
Alguns acham que a Gia é um robô humanoide, mas não. Humana como nós, vive apenas no mundo virtual. Ama roupas, maquiagens e acessórios que remetam ao futuro, mas também possui uma "pitada" alternativa e vintage.
A ideia principal é transitar pelo metaverso. Por enquanto, a Gia fará aparições em nossas redes sociais e também irá interagir com nossos clientes e fornecedores através de reuniões em plataformas on-line.

Muito temos que estudar para torná-la apta a exercer o papel de uma inteligência artificial. Tecnologias, redes neurais, algoritmos, etc. Através do Machine Learning, Deep Learning e PLN, esperamos evoluí-la para interagir com postura natural, inteligente e intuitiva.
Abaixo, um escopo dos passos que iremos realizar para alcançar o que esperamos:
Primeiro passo: Aquisição e processamento.
Precisamos obter e processar os dados que serão utilizados em nossa rede, assim, desenvolveremos os protótipos e algoritmos ideais. Estes, serão provenientes de fontes internas (criação e treinamento interno, conforme imagem abaixo) ou externas (dados captados no Google, por exemplo).
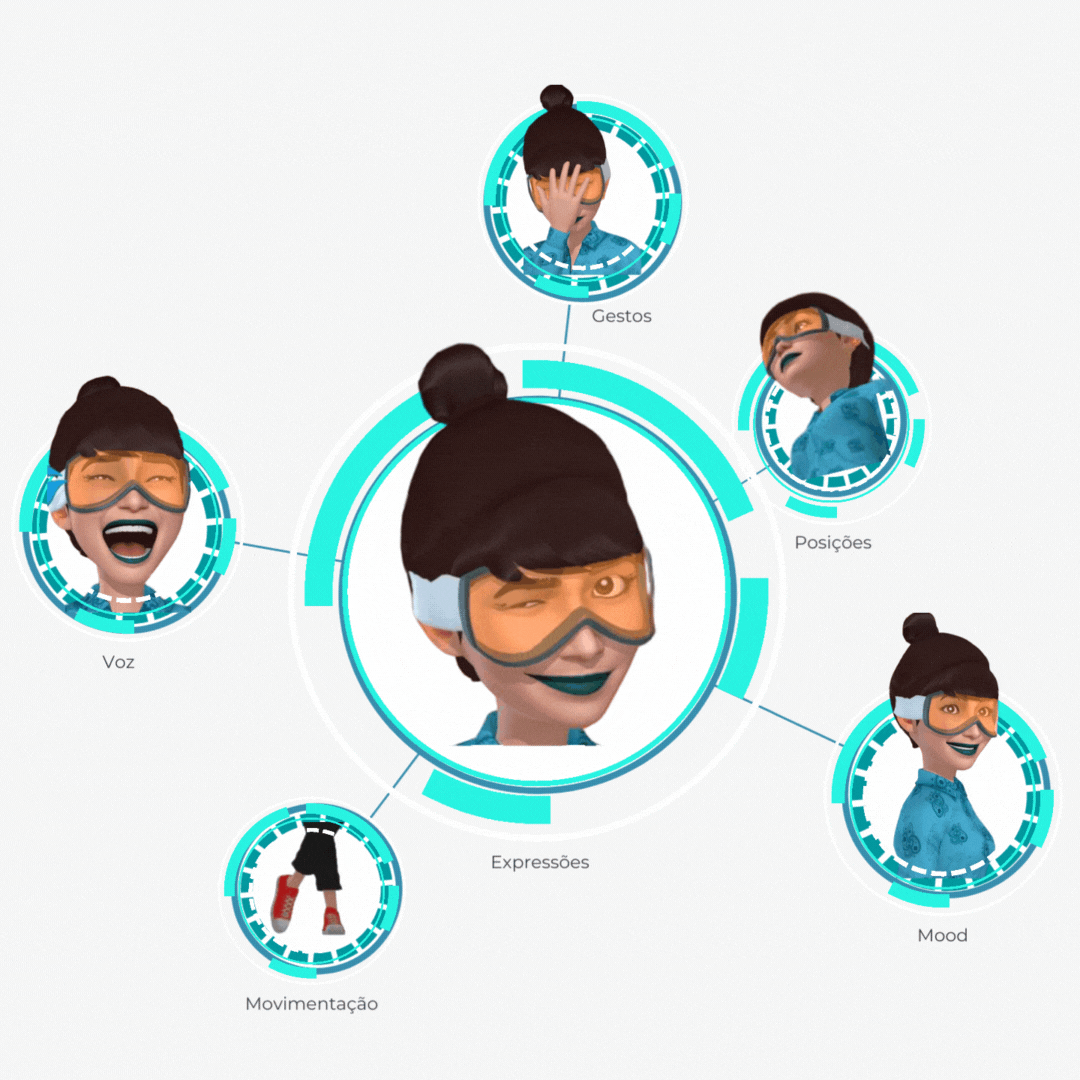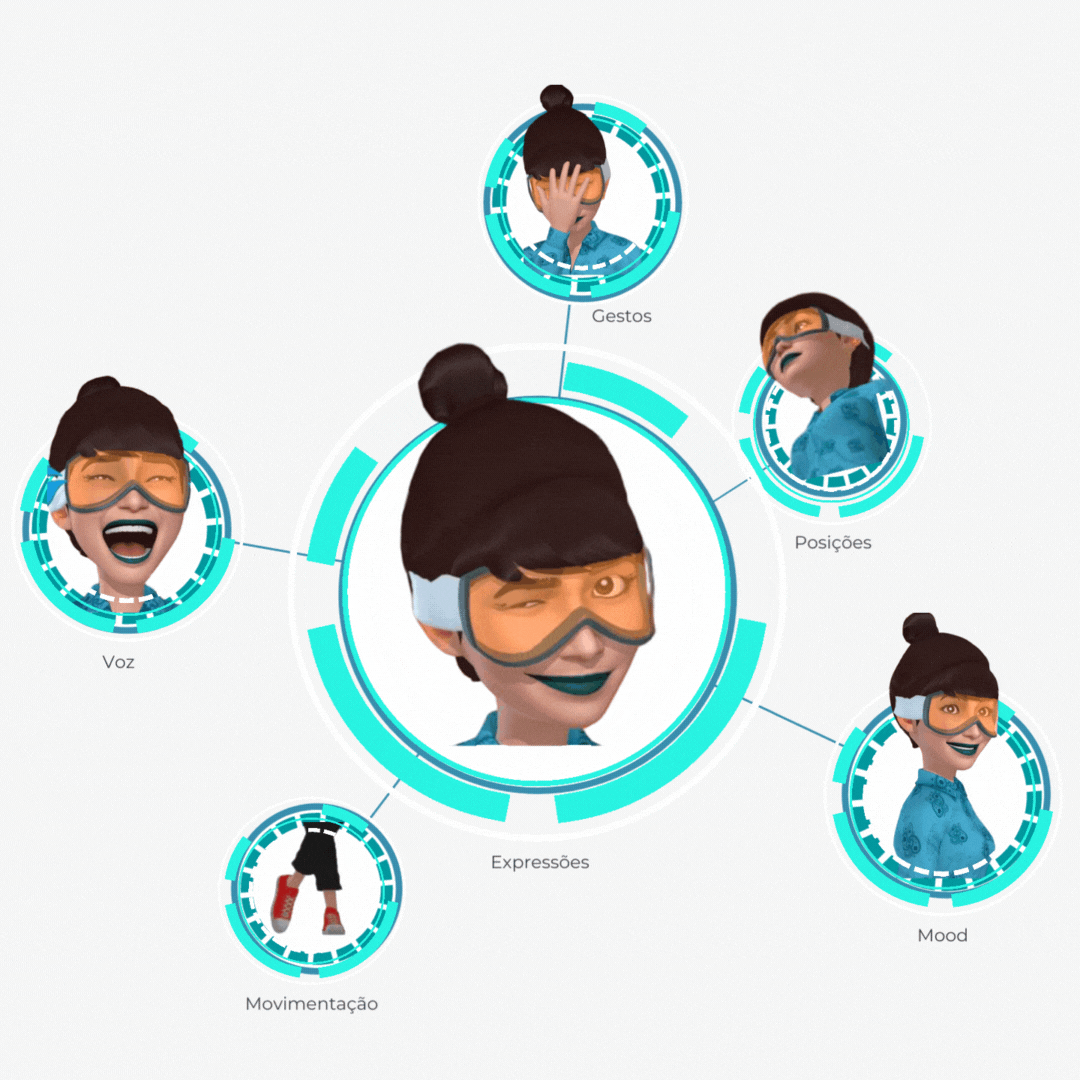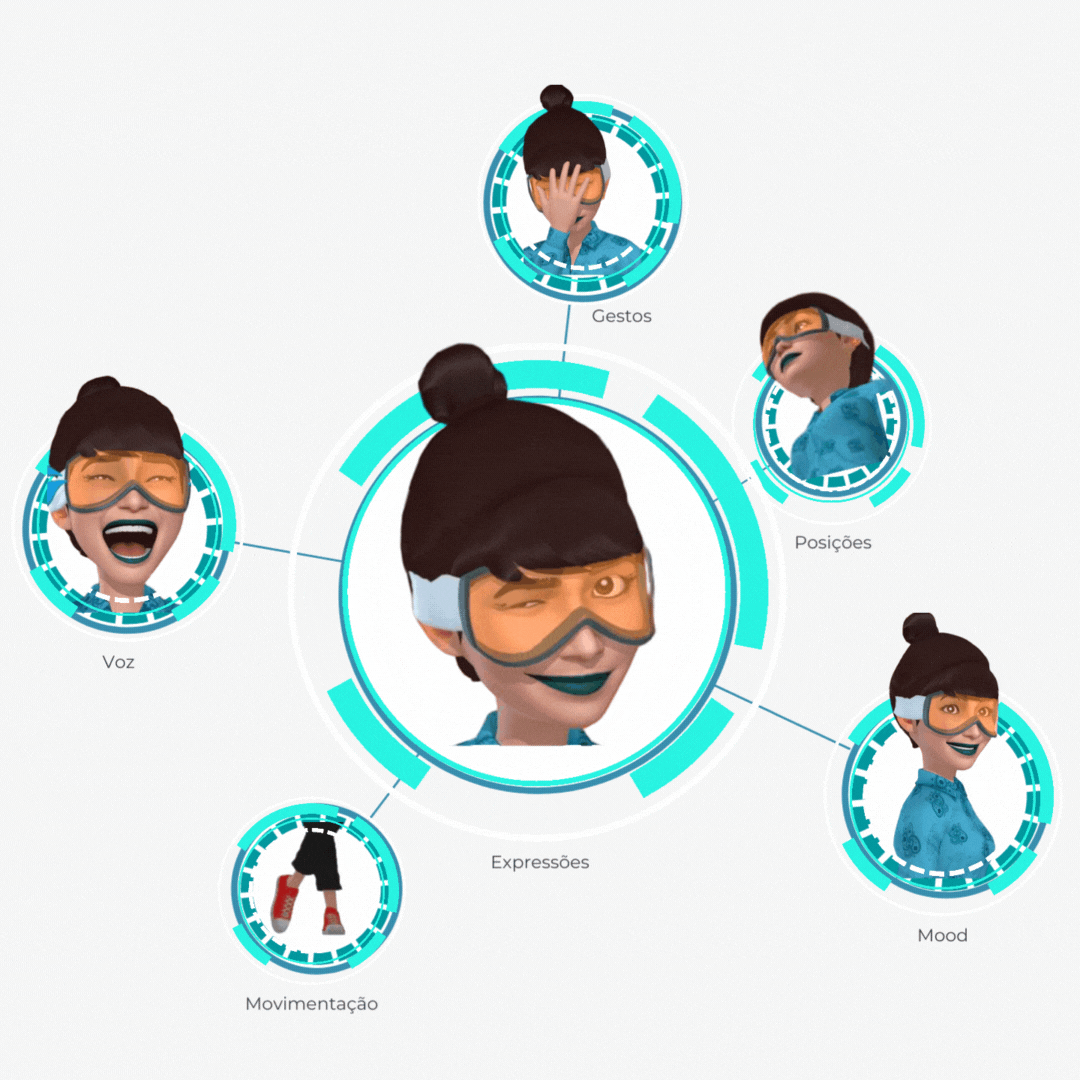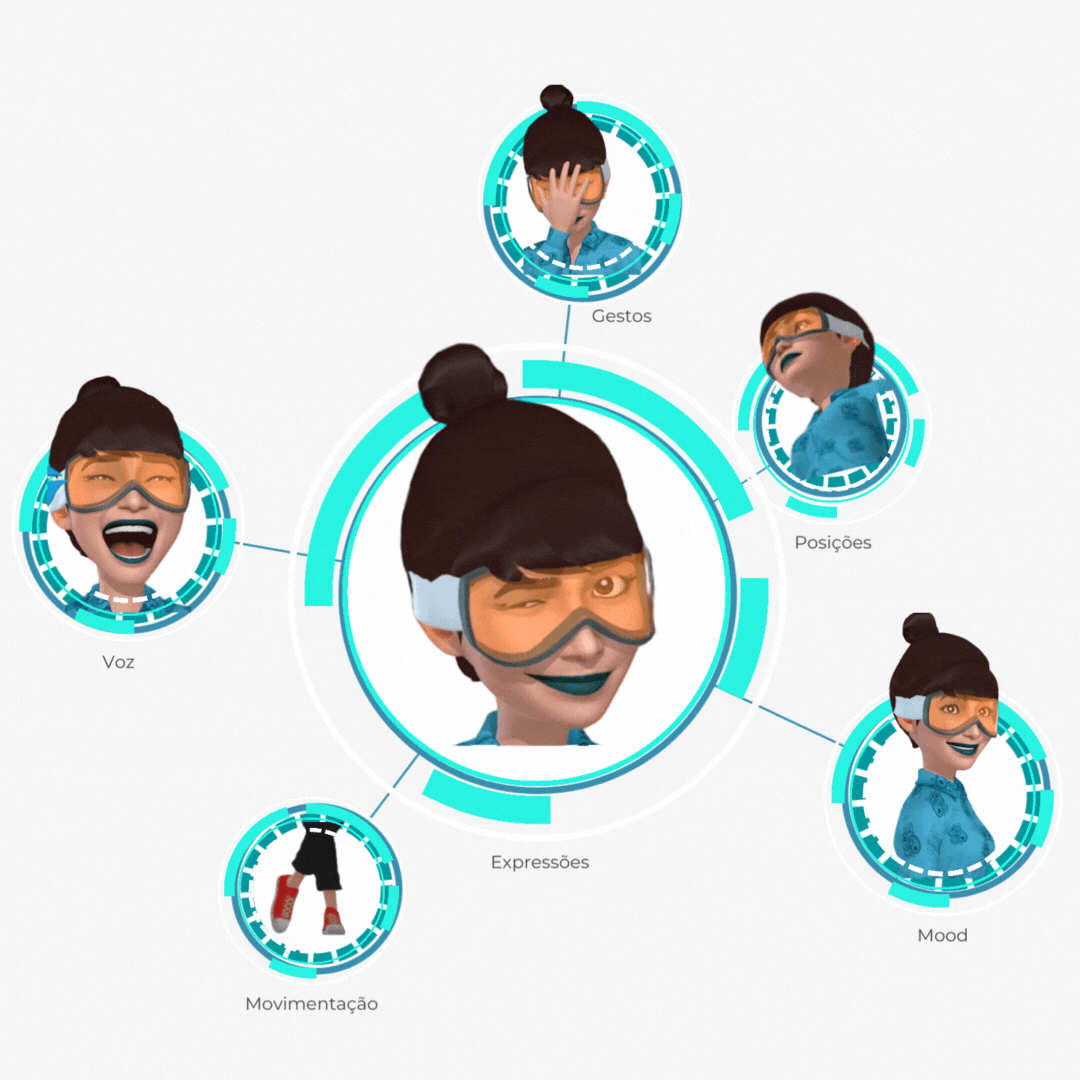
Segundo passo: Qualidade de dados obtidos.
Para desenvolver um conjunto de dados com características adequadas para nosso projeto, será necessário um alto grau de precisão. Eliminar todo tipo de ruído ou erro.
Se os dados conterem qualquer tipo de desbalanceamento, por exemplo, ensinar frases sem contexto, os algoritmos irão aprender de forma distorcida e as respostas tenderão a amplificar o erro.
Abaixo, exemplo de um treinamento incorreto do algoritmo. A pronúncia é OK, mas a Gia aprendeu NÃO OK.

Terceiro passo: Armazenamento.
Armazenar os dados e estruturá-los de uma forma com a qual sua disponibilidade seja alta, é uma tarefa difícil. Existem alguns objetivos em relação ao algoritmo que teremos que alcançar: Latência dos dados, resiliência, velocidade e conformidade.
Trabalhar com dados semelhantes aos da Gia são desafiadores. Quando se trata de projetos com IA, algoritmos que trabalham por aprendizado de voz e imagens, costumam conter muitos “dados ruins”.
A ideia é utilizar o armazenamento em banco de dados para garantir a alta disponibilidade. Atualmente, nos projetos de IA, sistemas em NoSQL estão cada vez mais frequentes porque não exigem restrições aos bancos de dados relacionais.

Quarto passo: Cyber Security.
Gerenciar a segurança, o acesso e a permissão de dados garantirão o uso adequado do sistema. Criar políticas também, para proteger os dados contra incidentes e violações.
Os dados são os componentes mais valiosos para projetos de IA. Caso se percam, não será possível reconstruir modelos iguais aos de origem. Um projeto iniciado do zero, demanda tempo e o novo algoritmo será similar, nunca idêntico. Por isso as leis de proteção à privacidade estão cada vez mais severas.

Quinto passo: Integração com sistemas.
Após feito todos os passos e conseguir garantir a disponibilidade de nossa IA junto à Gia, começaremos a integração com os sistemas do qual ela irá auxiliar-nos, por exemplo: redes sociais, reuniões online, suporte ao cliente e futuramente, sua integração com as máquinas. Isso trará uma IHM interativa com os operadores.

Ainda há muito o que estudar, estruturar e testar. Esperamos que gostem da nossa querida Gia e que sua evolução a partir daqui seja totalmente perceptível.